

对于需要挖掘洞察的首席营销官而言,数据质量至关重要,89%的采购方都认为这是他们的首要任务。本文将揭示欺诈行为的现状,并阐述Kantar如何借助人工智能及其他先进解决方案来解决这一问题。
对于需要挖掘洞察的首席营销官(CMO)而言,数据质量至关重要,89%的买家认为这是他们的首要任务(来源:《Greenbook》,2023年GRIT洞察实践报告)。
随着越来越多的买家、卖家和供应商意识到必须解决这一问题,最近一项行业质量承诺正获得越来越多的支持。
正如市场研究协会(Market Research Society)首席执行官简·弗罗斯特(Jane Frost)所言:“欺诈活动正变得日益狡猾,尤其是在在线调研领域。这对我们行业的未来构成了重大风险。”
数据质量本应是洞察购买者可以信赖的基本要素,但欺诈行为却已肆虐多年。而这在整个行业中却是一个奇怪地鲜少被讨论的话题。样本欺诈正逐渐演变成本十年的广告欺诈或点击农场——并且正在迅速走向工业化。
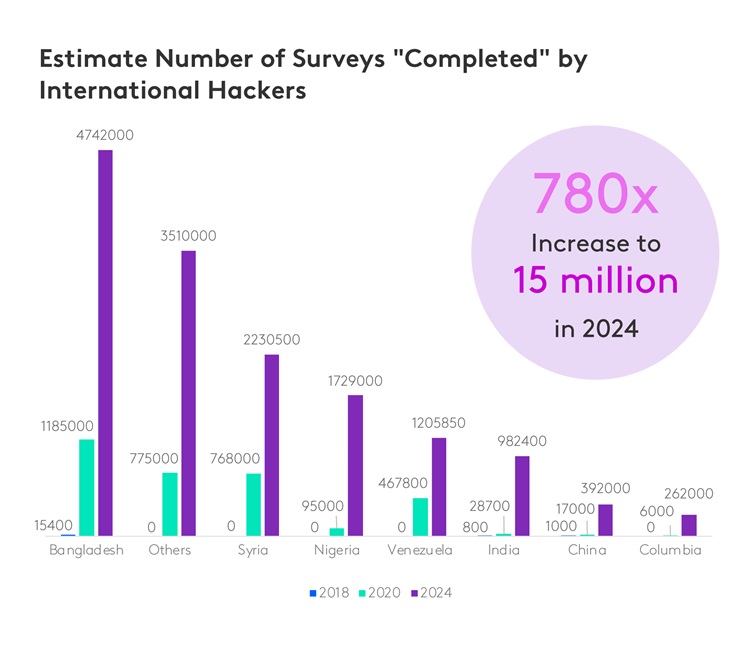
更糟糕的是,随着欺诈率的上升,由此产生的数据偏差也在加剧。
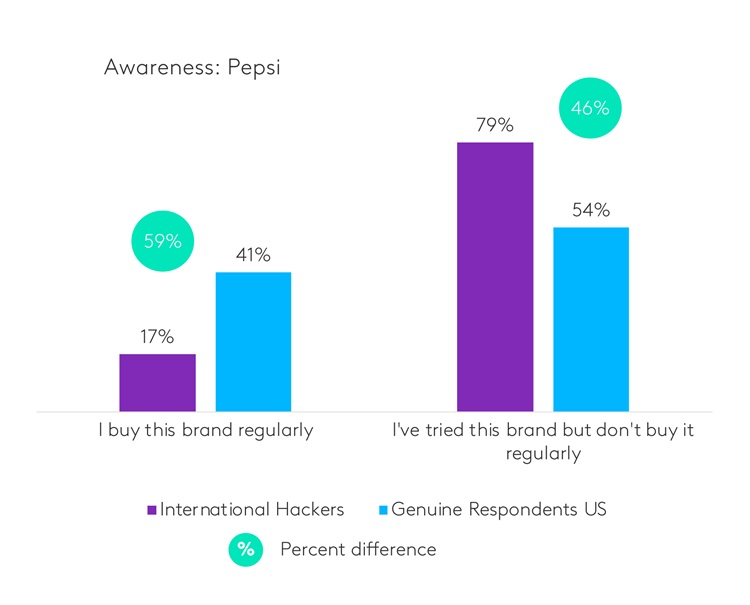
在本文中,我们将揭示欺诈问题的现状,以及Kantar如何借助人工智能和其他先进解决方案来解决这一问题。
全球范围内,有三大行业挑战影响着调研样本库:
1. 争夺受众注意力——我们如何争夺受访者宝贵的时间?
2.日益严格的数据隐私合规要求:例如,GDPR与CPPA存在差异。
3. 日益严重的在线欺诈问题。 “核对率”(即因质量低劣而被拒的样本所占比例)在过去三年中增长了约300%,且客户在实地调研后最多会拒收高达40%的数据。
样本库所有者必须以明智且具有战略性的方式应对这三个因素。
1. 争夺眼球
这一切始于我们对待受访者的方式——我们不将他们视为商品,而是视为宝贵的资源。我们不断探索如何优化提问方式、调整访谈时长(LoI)以及如何增强游戏化元素。通过回应他们的疑问并给予善待,我们将受访者视为有血有肉的个体。我们利用独特的调查匹配算法为每位受访者进行精准匹配,确保合适的人以合适的节奏完成合适的调查。 这有助于减少中途退出和筛选淘汰的情况,使我们的调查完成率比行业平均水平高出175%。通过将受访者视为受重视的个体与先进的受访者面板技术相结合,我们发现受访者既感到满意又积极参与。他们在Trustpilot上给我们的应用打出了4.2分的高分,并留下积极评价,例如:“氛围积极向上,我从在线调查中学到了很多,同时我的银行账户也一直‘笑’个不停!”
2. 日益严格的数据隐私合规要求
Kantar 在行业讨论和工作组(例如 ESOMAR)中发挥着领导作用。我们还拥有一支内部专家团队,持续关注隐私和同意相关法规,并确保我们具备正确的技术解决方案来采集、存储和删除数据。
例如在中国,我们拥有一个符合《个人信息保护法》(PIPL)的专用样本管理平台,用于开展经中国广告协会(CAC)批准的数据收集工作,并提供一系列针对中国市场的优化方案。 该平台完全部署于中国网络空间内,并可通过程序化方式接入我们全资拥有的微信移动调研面板,从而触达150万难以触及的受众。此外,我们还建立了多层反欺诈和质量检查机制,确保每个微信账号均关联真实且唯一的银行账户。ID和调查链接均采用MD5和Wave Secret进行加密处理,以防范幽灵完成及黑客的欺诈性回复。
3. 网络诈骗案件日益增多
超过三分之二的数据质量警示(69%)源于各类欺诈行为。 其中,41% 来自国际黑客,13% 来自已知机器人,7% 来自“幽灵完成”(即受访者看似完成了调查,但因设置了重定向链接而未收集到数据),8% 来自重复数据(即受访者完成多份调查,通常是他们创建了多个欺诈账户,伪装成不同的人口统计群体)。
为确保最高数据质量,我们将欺诈行为分为三类:
•缺乏参与度的受访者:他们边做其他事情边应答,机械地填完问卷,因此准确性存疑。对数据完整性的影响为中低程度。这类受访者需要指导和行为监控。可能需要将他们排除在某些研究之外。
•不诚实的受访者:他们谎报身份,通过完成更多调查来更快获取奖励。这对数据完整性的影响为中度至高度。
•欺诈性受访者:他们单独或结伙行动,通过破解调查系统批量获取奖励——这可以看作是新型的“点击农场”。这是严重的欺诈行为,规模庞大,对数据完整性的影响极大。
Kantar 针对上述每种欺诈行为采取了哪些措施?我们又是如何利用业界领先的 AI/生成式 AI 工具来应对这些欺诈行为的?
•我们倡导 优质的问卷设计:调查质量取决于设计、长度和用户体验。若忽视这些因素,即使是最积极的参与者也会失去兴趣。
•我们防止因疏忽导致的错误:部分受访者因误解而给出前后不一致的答案,也有人并非其自称的身份;但并非所有被标记的问题都源于蓄意欺骗。有些是无心之失,且并非所有被标记的行为都会损害数据完整性。我们希望包容所有真诚的参与者。 因此,我们会为受访者提供培训,并在必要时给予他们改进行为的机会。
•我们定义质量标准:质量虽具主观性,但我们采用客观指标。识别不同层级的质量问题及其成因至关重要。Kantar旗下Profiles部门凭借20余年的深度样本专业经验,结合技术与人工智能,通过其专有的反欺诈工具Qubed AI实现实时监测。 Qubed AI 实时运行,由 5 个深度神经网络(即先进机器学习)驱动,每日基于 6000 万余次事件进行训练,并针对每次调查会话处理超过 300 个特征,从而在毫秒内自动评分并给出判定结果及建议措施,以确定受访者是否存在欺诈行为——这是人类(及其他反欺诈技术)根本无法做到的。
•我们采用基于 Qubed 开放式验证的生成式人工智能(GenAI):我们使用基于 ChatGPT 的专有开放式评估解决方案,对受访者的开放式回答进行多维度评分。 我们检测的因素包括:与所提问题的相关性、原创性、完整性、语言表达、抄袭内容、个人身份信息(PII)的使用、俚语、缩写词,以及粗俗语言、种族歧视、无意义内容和ChatGPT生成的答案。如需进一步了解Kantar的Qubed开放式验证如何打击欺诈,请参阅我们此前发布的文章《变革调研样本:Kantar如何利用大型语言模型(LLMs)提升样本回答质量?》
•Qubed 面部验证的推出:Kantar 在打击调查欺诈方面的最新举措是将 Realeyes Verify 集成到我们的 Qubed AI 中。Verify 是一种轻量级面部验证技术,基于 1700 万次经受访者同意的调查会话组成的独特网络摄像头数据集进行训练。 我们能够迅速识别恶意行为者试图加入我们的优质样本库的情况。
首席营销官(CMO)和洞察负责人需要了解其样本库合作伙伴如何优先保障数据质量,并确保合作伙伴提供的数据及时准确、未受欺诈性回答的污染。
随着整个行业通过《质量承诺》及其他方式致力于提升质量,Kantar 凭借对 AI 的智能运用,已做好充分准备,将继续发挥领导作用,消除欺诈行为,并为消费者数据行业重塑更大信心。

.svg)